

Using an embedded web server, this functionality provides remote access to some of the PDF Explorer functionalities, currently the DBSearch and DBDiskTree scan modes. With the help of a common web browser, or any other technology able to execute HTTP requests, users can remotely search and view PDF Explorer indexed PDF's and CMH's in an environment similar to a web search engine.

Useful to access our home PDFE database from work, or vice-versa, using a common Internet connection, without the need to carry our precious document collection with us all the time.
A client-server architecture can be easily constructed, running a PDF Explorer web interface enabled instance at the server machine, where clients will access using web browsers from computers in the LAN, or even from any place in the world using the Internet.
Another advantage is that only a web browser is required to use the interface, so only the computer where PDFE is running needs to be a Windows system. Clients can use any OS (Linux, Mac OS, etc.) as long they provide a compatible web browser.
Technically, the web interface is provided by a embedded and dedicated HTTP server, so, some knowledge of how to run a common http server, such as the well known Apache or MS IIS, is needed to set our PDFE web server. Even so, the PDFE web server is much more simple, consequently much more easy to configure.
We can reach the functionality options and interface dialog from the Extra menu web Interface menu item, or from the respective PDFInfo view toolbar web interface tool button.
In the next image, the screenshot's composition of the tool configuration, and interface, dialog, in some of its functional stages.

Let's now introduce all the configurable options and functionalities.
For private LAN use there is no need to set up this functionality, but when we want to enable the web interface from large LANs or from Internet access this is really necessary or anyone will be able to access our indexed resources without restrictions.
This control is used to define web access permissions and restrictions. With it we can precisely define what web interface functionalities a specific user can, or can't, use.
Permissions are defined by groups. Clients/Users, identified by login username/password pair, and members of a specific group, inherited that group permissions and restrictions.

Two groups, Administrators and Guests, are system default and are always present in the list. The Administrator group has all the functionalities enabled and can't be edited. It is also this group the used when we have not set up any user in the system.
The Guests group is the group all unlogged users are members of, so, be careful when defining the permissions of this group.
Unchecking the guests group will force arriving users to go directly to the login page, since this page is the only content unlogged users can access.
To create a new group we just need to click the Add button. A new group, created with default settings, will show up in the list. We can give it a more meaningful name in the Group name edit box.
When enabled, the "DBDiskTree mode" provide access to an equivalent DBDiskTree GUI interface functionality. Users will be able to browse all the indexed folders contents using an indexed disks/folders tree.
Users will not be able to download/view the PDF, or CHM file, if the "Can consult PDF's" option is unchecked. They will only have access to the search results metadata.
The "can upload files", "can edit metadata" and "can rename, delete and move files", are group global permissions that can be used to temporally enable/disable respective functionalities, without the need to go to each folder, under the folder tab accessible folders tree, setting and unsetting that permission.
The "Available fields" check list, lists all the GUI defined grid layouts and is used to define the list of metadata fields groups web access users will be able to select. These field groups define what metadata fields are shown in the search results. A list box will appear in the web interface page when more than one of this group is checked, and user will be able to select between these available fields groups. From all the checked groups made available to members of this group, the selected one will be used as the default when the user accesses the web interface.
The "Accessible folders" tree, under the Folders tab, is used to define what indexed folders the members of the group have access to, so if a web interface search result links to a file present in an unchecked folder/disk, it will not be show up in the search results for users members of that group.
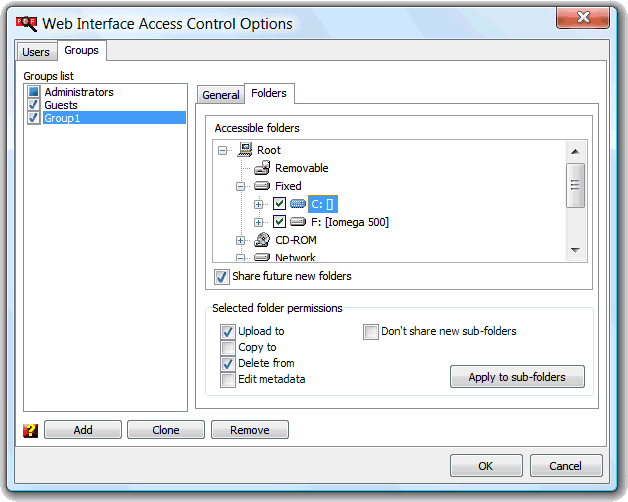
Note: Checking and unchecking this folder visibility state checkbox also sets its subfolders state. Just press CTRL in order to only set it own state.
The "Share future new folders" is used to automatically share any folder not currently present in the indexed resources tree but which may appear later when added by the administrator, using the PDFE GUI to index new resources into the PDFE database. Disabling this option ensures that later this new indexed folders/disks contents will not show up in the web interface search results. Finer control can be achieved using the folder permission option "don't share new sub-folders", that, if the global share future folders is enabled, will prevent the sharing of futurely indexed sub-folders of that particular folder.
It is also in this tab we can define the specific folder permissions. Dependent on the state of the equivalent group global permission, the selected folder can be configured to accept the upload and copy to, delete from, and edit metadata functionalities. The apply to subfolders button will propagate selected folder set permissions to its subfolders.
In the Users tab we create and define users. A user is defined by a username/password pair and by a connection to a defined permissions group.

The use of this dialog is straight forward. "Add" button to add new user to the list, "Remove" button to remove the select user from the list, "Username", "Password" and "Member of" to set up the user. A Login link will appear in the web interface page, top right of the page, which the user must use to login into the system in order to use the functionalities assigned to the group he is member of. If guests group is disabled, the login page will show up immediately whenever an unlogged user accesses the web interface.
In order to access our PDFE web interface from the Internet we need to know our public IP address and point our browser to that address, e.g. http://169.132.10.34, or map it to a hostname using a DNS server and point our browser to that hostname, e.g. www.mysite.com. The Domain Name System (DNS) primarily serves as the "phone-book" for the Internet, translating human-readable computer hostnames, e.g. www.mysite.com, into IP addresses, e.g. 169.132.10.34. The IP address (Internet Protocol address) is a unique address that certain electronic devices use in order to identify and communicate with each other on a computer network utilizing the Internet Protocol standard (IP), in simple terms, is the unique ID used to identify a device in the network, so other devices can address communication with that device. In our context, the IP address is the unique ID of our PC where PDFE is running. Normally, when we connect to the Internet using our home dialup or ADSL service, our machine public IP address is dynamically assigned by our ISP, and changes each tim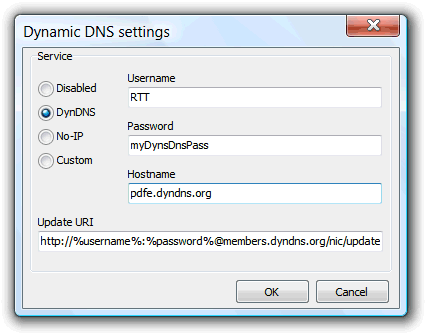 e we connect. Because of this change, we need to always know what our IP is at a given time. Memorizing the variable IP address is not practical, so, a human-readable hostname is much better. Because the IP changes, the DNS mapping needs to change accordingly. This Dynamic DNS functionality is used to automate this update process in real time. When enabled, every time the PDFE Web server starts, our public IP address will be communicated to our dynamic DNS provider. This way we can be sure our hostname will always resolve to our new PC public IP.
e we connect. Because of this change, we need to always know what our IP is at a given time. Memorizing the variable IP address is not practical, so, a human-readable hostname is much better. Because the IP changes, the DNS mapping needs to change accordingly. This Dynamic DNS functionality is used to automate this update process in real time. When enabled, every time the PDFE Web server starts, our public IP address will be communicated to our dynamic DNS provider. This way we can be sure our hostname will always resolve to our new PC public IP.
There are many free, and commercial, dynamic DNS providers in the Internet. Their service is to map a given IP address to a user defined hostname and to update the map every time our IP address change. The IP update solicitation uses a simple Internet http request to the dynamic DNS provider and it is this request that this PDFE functionality executes.
Normally we only need to create an account on these DDNS providers, select the hostname we want to use, and get from their information pages the URL request format needed to communicate the IP change. This tool provides two pre-configured requests, from two well know providers, and a custom one to use with other providers. The %username%, %password% and %hostname% variables map to the Username, Password and Hostname fields respectively, and the %ip% variable maps to our public IP address. Use these variables to construct the HTTP request URL when using another service provider.
Example for the DynDNS provider: http://%username%:%password%@members.dyndns.org/nic/update?system=dyndns&hostname=%hostname%&myip=%ip%&wildcard=NOCHG&mx=NOCHG&backmx=NOCHG&.
Use this dialog to enable/disable and configure the HTTPS protocol connection. Not going into details, HTTPS protocol connections uses cryptography techniques to obfuscate the traffic between server and client, making much more difficult for anyone to intercept and understand the data exchanged between server/client, maintaining communications privacy. When enabled and properly configured, HTTPS connection will be used automatically to logon and by all logged users connections.

To work, the protocol needs access to a signed digital certificate and a private key files, "Server Certificate" and "Server Key" fields of this dialog.
The certificate, sent to clients connecting using the https protocol, contains identification information related to the certified domain, the trusted certificate authority (CA), and the server's public encryption key. Client browsers may contact the server that issued the certificate (the trusted CA as above) and confirm that the certificate is authentic before proceeding.
Clients use the server certificate public key to encrypt protocol keys, these keys can only be decrypted by the server private key. This is the one fact that makes the keys hidden from third parties, since only the server and the client have access to this data.
Normally browsers maintain a list of trusted certificate authorities and warm users if the certificate was not signed by one of these authorities. As usual with this things, to sign a certificate these authorities charge some amount, and this amount varies with the level of security of the certificate. The level of the certificate doesn't change anything in the quality of encryption used. Better level means only the CA have used more strict identification procedures to check certificate owner identity.
The use of these trusted CA's services is only needed when we really need to enable access to the web interface by users we don't know, and may refuse the connection if the browser warns them because of certificate signed by unknown CA.
For private use we can sign your own certificates, called self signed, and force the browser to accept them.
Because the private key security is fundamental, anyone with access to the server can steal your private key file, we can encrypt it using a passphrase at generation time. Server may ask for this passphrase at startup, or, if used and you really hare sure no one will steal your private key file, passphrase may be saved with the dialog options.
To start with the private key and server certification generation, we just need to use the Certificate Generation Wizard.
This wizard can generate a ready to use SSL self-signed certificate or a certificate signing request (CSR).

The certificate signing request need to be signed by a certificate authority (CA) to become a functional web server SSL certificate. Both options also generate the related private key file.
Both wizard generation options share the, below image, form.

Filling almost all of these fields is straight forward and only the "Common Name" deserve special attention. This field is used to specify the domain name used to access the PDFE Web Server. Client browsers will complain about the certificate authenticity if the certificate common name don't correspond to the domain of the address typed to access the web server. So, if we only want to test locally in the server PC, localhost is the right name, if it is going to be accessible from the LAN, the server network PC name, e.g. xptoPC, must be used. If accessible from the Internet, the domain name mapped to the web server PC external IP, e.g. www.mysite.com, is the right choice. The IP number, local for LAN access or external for Internet access, is also a viable option if later it is used in the client browser as address to access the web server.
Longer key lengths are equivalent to more encryption effectiveness or strength, but for CSR generation we must check what key lengths the CA we want to use is able to sign. Also, old browsers, with only 40 bit encryption capabilities, only allow 512 bits key lengths certificates..
To protect the private key, a good strength password can be set in the passphrase field.
In the next wizard step, available after, at least, the mandatory fields are properly filled, we have the possibility to:
For "self-signed certificate generation":
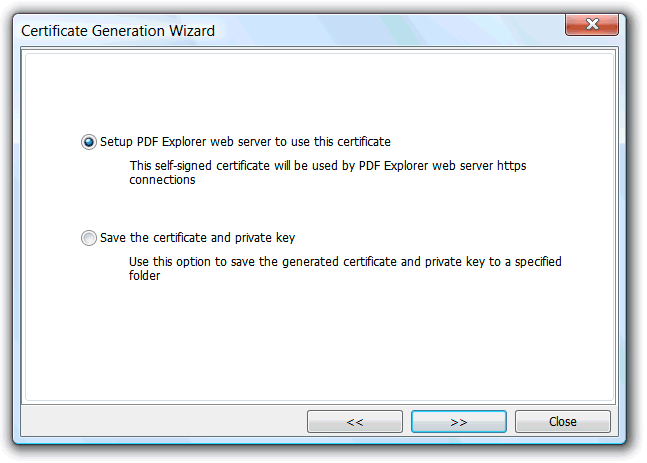
- Setup PDF Explorer Web Server interface to use this generated certificate. The new certificate and private key files are saved to the PDF Explorer data folder, overriding old files if present, and setup the Web Server HTTPS options to use this new certificate, key file and pass phrase.
- Save the generated certificate and private key files to a user selected folder.
For CSR generation:

- The Base64 encoded certificate request file shows up. At this step there is the possibility to copy it to the clipboard, and proceeding to the next wizard step, we will be able to save the CSR and private key files to a user selected folder.
The PDFE Web server isn't limited to provide the basic PDFE Web Interface, but can also be used to run a small web site. Basic HTML pages are enough to develop a simple web site, but script languages, e.g. PHP, PERL, and CGI's, support are nowadays essential.

This dialog is used to set the CGI's applications folder, and its alias, and to associate file extensions to a CGI or ISAPI interpreter in order to feed scripted pages (php, perl, etc). The above screen capture illustrates its use.
In the general options we can enable/disable the Multi-language functionality of the basic PDFE Web Interface. When enabled, a set of country flag images will show up at the top of the html pages, enabling client users to change his web interface language. In order to select the remote user default language, automatic browser language detection is also tried and the browser preferred language, if in the list of available ones, will be selected as default for remote user first connection request.
When disabled, the default web interface language reverts to that used in the PDF Explorer GUI.

The extended web server Interface, web server root directory field, can be used to easily extend the web interface with custom content. When set, the domain name of our site will map to this root directory, with the PDFE web interface remaining accessible at the http://<domain>:<port>/pdfews/ virtual directory.
Here is a practical example of a custom content folders tree organization.
C:\MySite
├───perl
├───php
├───utils
└───wwwroot
├───cgi-bin
├───css
├───images
└───js
Pointing the field, as in the above screenshot, to the wwwroot directory, and putting an index.html file there (or .php, .pl, etc., if CGI/ISAPI interpreters for these extensions are set), will instruct the web server to feed this file when domain root requested. This extended web server functionality is very simple, and almost all it can do is to feed requested files. But it is perfectly capable of running a simple web site that doesn't need to be directly related to the PDF Explorer web interface, and it's also a simple way to feed a custom developed, and more advanced than the default html template based, web interface client using the web interface API.
Used to set directories alias. These alias are normally used to map a complex folder to a more simple, and single, word.

These alias are used to construct web link addresses as if the full directory was used. The PDFE WS will replace the alias, and search for the requested file in the directory the alias is mapped to.
Directories outside the specified web server root directory are allowed, and an example of this use is the "pdfews" alias, automatically created by PDFE and always present in the virtual directories list. The "pdfews" alias maps to the webserv sub-folder where PDF Explorer is installed and is essential to enable the access to the basic PDFE Web interface and at same time enable the extension of the Web server with user custom content.
Used to block or enable accesses to the web interface, based on basic rules. Access can be blocked/granted by user agent name, remote client IP address or address range, and by referrer address.

The above screen capture shows one example for all these rules. Setting the "Allow only" option will enable access only to clients within the overall rules list. On the other hand, the "Disallow all" option will block access to any of the clients with at least one property equal to one of the rules in the list.
The "Ban spider robots" option creates a virtual robots.txt file, when requested by clients, informing compliant robots they shouldn't access any web site content. Only works with robots that respect these standard robots.txt rules.
Here is the content of that robots.txt virtual file:
Useragent: *
Disallow: /
This option does nothing if a robots.txt file is present at the web site root folder, being that custom robots.txt the one sent when requested by clients.
All access to the web interface can be logged to a file using the NCSA Combined Log Format.

This additional option dialog is used to enable/disable the logging feature, set the log file output directory and the log file rotate schema. File rotate specifies the time interval, or maximum file size, used to backup the, in use, log file and create a new one.
Partitioning log files is important because software, or hardware, crashes can always damage the active log file, and, eventually, all the data in it.
This functionality enables the possibility to show the indexed documents visual representation, in the form of an image file (usually the miniature of that representation, the thumbnail), of the first document page, at the web interface clients.

The thumbnail image files must be generated by an external tool, no embedded thumbnail generator is available at this time. To generate this there are two possible methods:
The web server will search for the requested thumbnail at the "Thumbnails cache folder", and, if not found, call the configured thumbnail generator for the requested file type. The configured "Default thumbnail image" will be sent if no generator is configured, or if the generator returns and thumbnail file continues missing. If no default thumbnail is set, a default 256x256 noimage.png will be send instead.
The external generator source can be set to the Windows assigned, of that file type, "Shell Thumbnail Handler", or a custom defined command line program, or script.
A thumbnail handler is a Windows Shell Extension responsible to generate the thumbnail images that user can see in the Windows Explorer thumbnail view mode and, since Windows Vista, in almost all the Shell dialogs. Usually, Acrobat Reader provides this Shell extension, being a quick solution to enable thumbnails visualization from the web interface clients. When the thumbnails source is set to this option, there is the possibility to specify the image size, width and height, for the "small" and the "Big" representations. More information about how these two representation are used can be checked in the web interface API, GetThumbnail function, description.
However Shell Thumbnail Handlers are a bit limited, as the image size is almost the only parameter that can change. To enable further possibilities there is also the option to set as thumbnail source an "External generator" (a command line application or script). The option requires the configuration of the "Thumbnails generator" settings. As exemplified in the above screenshot, this option must point to an external, command line activated, application, or script file, and include, at least, the reference to the two required parameters : [in], to specify the document from which to make the thumbnail, and [out], to reference the output image file name. A comma character must be included just after the generator full path+name, to separate the application to call, from the parameters to pass.
The [in] reference will be replaced, at call time, by the full path to the document from which to make the thumbnail, and the [out] by the, web server generated, output full path and name, without a file extension, the web server will search as generated thumbnail image file. The file extension is not specified in this output file name because any html supported image file type can be used. Its the external thumbnail generators responsibility to append the file extension of the effectively created image file type. This doesn't invalidate that file extension being provided right from the parameters (entering "[out].png" is one of the obvious possibilities) if external application require a file extension on that output file name parameter.
Double quotes around the "[in]" and "[out]" references are normally needed to properly pass filenames and paths with spaces.
Passing additional parameters from the web interface client to the thumbnail generator is possible with the use of the [c#] variables (replace # by an integer number>=1). This variable index (#) must always start at 1, and sequentially increment by one, if additional variables used.
C:\MySite\utils\\thumbgen.exe, "[in]" -page [c1] -quality [c2] "[out]"
Check the GetThumbnail API call function, for further details on the use of this variables.
The web server will search for the requested thumbnail at the "Thumbnails cache folder", and, if not found, the configured "Default thumbnail image" will be sent. If no default thumbnail set, a default 256x256 noimage.png will be send instead.
There is only the need to use the file name scheme to name these image files, and this schema is pretty simple. Take the document full path and name, and delete all the "<>:\?|." character occurrences on that string. So, if we have a "C:\My Documents\PDFs\a document name.pdf" we need a image filename at the configured "Thumbnails cache folder", named "CMy DocumentsPDFsa document namepdf.gif (or .jpg, .png, or any other html image supported file type). The source PDF, or CHM, document file name, used to derive the thumbnail file name, uses the same schema used in PDF Explorer, so, if we have a source PDF inside a compressed zip file, we have something like "C:\My Documents\PDFs\<an archive name.zip>a folder\a document name.pdf", so we will need a image named "CMy DocumentsPDFsan archive namezipa foldera document namepdf.gif"
From Wikipedia: "OpenSearch is a collection of technologies that allow publishing of search results in a format suitable for syndication and aggregation. It is a way for websites and search engines to publish search results in a standard and accessible format."
And this technology is also available through the PDF Explorer web interface, with RSS, ATOM, and HTML, response formats, enabling search aggregators, or other tools able to execute OpenSearch requests and handle available responses formats, to access the web interface exposed PDFE database records.
A suitable OpenSearch client plugin is located at: http://<domain>:<port>/pdfews/opensearch.xml
Modern Internet browsers are OpenSearch enabled, with possibility to add OpenSearch client plugins to the list of search providers.

To install the client plugin, to the list of available browser search providers, there is only the need to navigate to a PDFE web interface page, even if that page is being provided by a remote computer, so, there is no need to have PDFE installed. The browser, using the "auto discover" technique, will find the OpenSearch client plugin and enable user with the option to add it as a search provider. Once the provider is on the browser list, the user can perform a search even without previously opening any PDFE web interface page. The browser already knows the address, so, as long the remote computer at that address is running the web interface, the search results will show up.
This API expose a simple RESTful based interface, able to provide the possibility to design web interface clients completely independent of any html template, being the only requirement for the ability to execute HTTP GET, and POST, requests, and handle the provided file format responses, to access all the PDF Explorer web interface functionalities. This, obviously, includes the possibility to develop clients not web browser based, using any development technology that's able to execute HTTP requests and handle any of the provided response formats.
A web 2.0 style, fully functional and ready to use, web interface client, that makes uses of this API, is available to download, and comment, from the PDF Explorer support forum at: http://www.rttsoftware.com/forum/index.php?topic=322.0
Source code included, so very helpful to better understand this API.
The API requests are invoked using the next URL address schema:
http://<domain>:<port>/pdfews/apicall?f=FunctionName&Param1=Value&Param2=Value...
An HTTP request to the /pdfews/apicall virtual folder, passing the name of the, server site, function to execute in a f named parameter, plus any of the, function specific, additional parameters.
Depending on the function, there are various data response formats available to choose from. This way client developers can choose the one more suitable to the development technology used.
This response data format selection is achieved by the format, common to all requests, parameter, that depending of the function being requested, can have one of the next values:
Filename,Title,Subject,Author,Keywords,Pages,Security,Version "HSR_25.pdf","Canada and The European Space Agency","Three Decades of Cooperation","Lydia Dotto","HSR-25","31","0","1.5" "HSR_26.pdf","Spain in Space","A short history of Spanish activity in the space sector","José M. Dorado, Manuel Bautista , Pedro Sanz-Aránguez, Drs. IA","HSR-26","41","0","1.5"
<?xml version='1.0' encoding='UTF-8'?>
<rss version="2.0"
xmlns:openSearch="http://a9.com/-/spec/opensearchrss/1.0/"
xmlns:pdfe="http://www.rttsoftware.com/pdfens/1.0/">
<channel>
<generator>PDF Explorer 1.5.0.59</generator>
<title>hsr - PDF Explorer - DBSearch</title>
<link>http://localhost/pdfews/apicall?f=DBSearch&q=hsr&start=0&sort=1&
dir=ASC&stype=0&format=rss&layout=1&count=2&cs=0&wo=0</link>
<description>PDF Explorer database query results</description>
<pubDate>Wed, 13 Jan 2010 00:12:32 GMT</pubDate>
<image>
<title>hsr - PDF Explorer - DBSearch</title>
<url>http://localhost/pdfews/images/logo_64.png</url>
<link>http://localhost/pdfews/apicall?f=DBSearch&q=hsr&start=0&sort=1
&dir=ASC&stype=0&format=html&layout=1&count=2&cs=0&wo=0</link>
</image>
<openSearch:totalResults>14</openSearch:totalResults>
<openSearch:startIndex>1</openSearch:startIndex>
<openSearch:itemsPerPage>2</openSearch:itemsPerPage>
<item>
<title>HSR_25.pdf</title>
<link>http://localhost/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F25.pdf</link>
<description>Canada and The European Space Agency</description>
<pdfe:subject>Three Decades of Cooperation</pdfe:subject>
<pdfe:author>Lydia Dotto</pdfe:author>
<pdfe:keywords>HSR-25</pdfe:keywords>
<pdfe:pages>31</pdfe:pages>
<pdfe:version>1.5</pdfe:version>
<pdfe:security>0</pdfe:security>
</item>
<item>
<title>HSR_26.pdf</title>
<link>http://localhost/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F26.pdf</link>
<description>Spain in Space</description>
<pdfe:subject>A short history of Spanish activity in the space sector</pdfe:subject>
<pdfe:author>José M. Dorado, Manuel Bautista , Pedro Sanz-Aránguez, Drs. IA</pdfe:author>
<pdfe:keywords>HSR-26</pdfe:keywords>
<pdfe:pages>41</pdfe:pages>
<pdfe:version>1.5</pdfe:version>
<pdfe:security>0</pdfe:security>
</item>
</channel>
</rss>
<?xml version='1.0' encoding='UTF-8'?>
<feed xmlns="http://www.w3.org/2005/Atom"
xmlns:openSearch="http://a9.com/-/spec/opensearchrss/1.0/"
xmlns:pdfe="http://www.rttsoftware.com/pdfens/1.0/">
<generator>PDF Explorer 1.5.0.59</generator>
<title>hsr - PDF Explorer - DBSearch</title>
<link rel="self" type="application/atom+xml"
href="http://localhost/pdfews/apicall?f=DBSearch&q=hsr&start=0&sort=1&
dir=ASC&stype=0&format=atom&layout=1&count=2&cs=0&wo=0"/>
<link rel="alternate" type="text/html"
href="http://localhost/pdfews/apicall?f=DBSearch&q=hsr&start=0&sort=1&
dir=ASC&stype=0&format=html&layout=1&count=2&cs=0&wo=0"/>
<updated>Wed, 13 Jan 2010 00:12:32 GMT</updated>
<logo>http://localhost/pdfews/images/logo_64.png</logo>
<openSearch:totalResults>14</openSearch:totalResults>
<openSearch:startIndex>1</openSearch:startIndex>
<openSearch:itemsPerPage>2</openSearch:itemsPerPage>
<entry>
<link href="http://localhost/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F25.pdf"/>
<title>HSR_25.pdf</title>
<content type="html"><![CDATA[...]]></content>
<SRFilePath><pdfe:filePath>%FilePath%</pdfe:filePath></SRFilePath>
<SRFileSize><pdfe:fileSize>%FileSize%</pdfe:fileSize></SRFileSize>
<pdfe:subject>Three Decades of Cooperation</pdfe:subject>
<pdfe:author>Lydia Dotto</pdfe:author>
<pdfe:keywords>HSR-25</pdfe:keywords>
<pdfe:pages>31</pdfe:pages>
<pdfe:version>1.5</pdfe:version>
<pdfe:security>0</pdfe:security>
</entry>
<entry>
<link href="http://vistapc/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F26.pdf"/>
<title>HSR_26.pdf</title>
<content type="html"><![CDATA[...]]></content>
<SRFilePath><pdfe:filePath>%FilePath%</pdfe:filePath></SRFilePath>
<SRFileSize><pdfe:fileSize>%FileSize%</pdfe:fileSize></SRFileSize>
<pdfe:subject>A short history of Spanish activity in the space sector</pdfe:subject>
<pdfe:author>José M. Dorado, Manuel Bautista , Pedro Sanz-Aránguez, Drs. IA</pdfe:author>
<pdfe:keywords>HSR-26</pdfe:keywords>
<pdfe:pages>41</pdfe:pages>
<pdfe:version>1.5</pdfe:version>
<pdfe:security>0</pdfe:security>
</entry>
</feed>
<?xml version='1.0' encoding='UTF-8'?>
<pdfexml version="1.0" xmlns="http://www.rttsoftware.com/pdfens/1.0/">
<generator>PDF Explorer 1.5.0.59</generator>
<title>hsr - PDF Explorer - DBSearch</title>
<link>http://localhost/pdfews/apicall?f=DBSearch&q=hsr&start=0&sort=1&
dir=ASC&stype=0&format=xml&layout=1&count=2&cs=0&wo=0</link>
<description>PDF Explorer database query results</description>
<pubDate>Wed, 13 Jan 2010 00:12:32 GMT</pubDate>
<totalResults>14</totalResults>
<startIndex>1</startIndex>
<itemsPerPage>2</itemsPerPage>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F25.pdf</fileURL>
<Filename>HSR_25.pdf</Filename>
<Title>Canada and The European Space Agency</Title>
<Subject>Three Decades of Cooperation</Subject>
<Author>Lydia Dotto</Author>
<Keywords>HSR-25</Keywords>
<Pages>31</Pages>
<Version>1.5</Version>
<Security>0</Security>
</entry>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F26.pdf</fileURL>
<Filename>HSR_26.pdf</Filename>
<Title>Spain in Space</Title>
<Subject>A short history of Spanish activity in the space sector</Subject>
<Author>José M. Dorado, Manuel Bautista , Pedro Sanz-Aránguez, Drs. IA</Author>
<Keywords>HSR-26</Keywords>
<Pages>41</Pages>
<Version>1.5</Version>
<Security>0</Security>
</entry>
</pdfexml>
{
"version": "1.0",
"encoding": "UTF-8",
"generator": "PDF Explorer 1.5.0.59",
"title": "hsr - PDF Explorer - DBSearch",
"link": "http://localhost/pdfews/apicall?f=DBSearch&q=hsr&start=0&sort=1&
dir=ASC&stype=0&format=json&layout=1&count=2&cs=0&wo=0",
"description": "PDF Explorer database query results",
"pubDate": "Wed, 13 Jan 2010 00:12:32 GMT",
"totalResults": "14",
"startIndex": "1",
"itemsPerPage": "2",
"entry": [
{
"fileURL": "/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F25.pdf",
"Filename": "HSR_25.pdf",
"Title": "Canada and The European Space Agency",
"Subject": "Three Decades of Cooperation",
"Author": "Lydia Dotto",
"Keywords": "HSR-25",
"Pages": "31",
"Version": "1.5",
"Security": "0"
},
{
"fileURL": "/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/HSR%5F26.pdf",
"Filename": "HSR_26.pdf",
"Title": "Spain in Space",
"Subject": "A short history of Spanish activity in the space sector",
"Author": "José M. Dorado, Manuel Bautista , Pedro Sanz-Aránguez, Drs. IA",
"Keywords": "HSR-26",
"Pages": "41",
"Version": "1.5",
"Security": "0"
}
]
All the response formats data is UTF-8 encoded.
Another parameter, common to all the functions, is named lng, and it's used to specify the active language when returning text messages, or interface text fields. Its value must follow the RFC 1766 language tags schema, as used by the HTTP Language Tags (en, pt-BR, etc). Web server will try to get the preferred language from the Accept-language HTTP header, if lng parameter is not specified, and will use the PDF Explorer GUI interface in use language if the requested language is not in the list of available ones.
When the client is Internet browser based, it's recommended to use a cache buster parameter, with GET requests that access data that can change often, in order to trick the cache mechanisms of the browser. This nonsense, to server, random name and/or value parameter makes the, always equal to server, requested url always different to the browser cached responses.
IsLoginNeeded - To know if users must login before send any other request. Login is not needed if there are no defined users, under the user's and permissions settings, meaning any request will be processed in the default Administrators group account.
IsGuestAccountEnabled - To know if the guests account (username=guest and password=guest) is enabled.
Login - Used to request user login
GetFeatures - Returns logged on user list of web interface enabled features. Useful to better develop dynamic clients, able to adapt the interface to the list of features the user has effectively access too.
GetMetadataFieldsListInfo - Returns the list of the PDFE defined grid layouts the logged user has access to. Includes the layout name and its included metadata fields characteristics (name, data type, text alignment and if it's editable field).
DBSearch - Performs a database Boolean search for the passed keywords. Equivalent to the GUI DBSearch scan mode.
GetDatabaseTree - Returns the database indexed folders tree. Data needed to know what folders are indexed in the PDFE database in order to execute DBFolder requests, and fill a tree GUI control, so client users can better perform these requests.
DBFolder - Returns all the metadata records of the requested, PDFE database indexed, folder. Equivalent to the GUI DBDiskTree scan mode.
GetThumbnail - Returns the passed document name image thumbnail.
SetMetadata - To edit a specified indexed document metadata field(s). Equivalent to the GUI InfoEdit tool.
Upload - To upload a file(s) to an PDFE indexed, and upload enabled, folder.
GetUploadState - To get upload statistic values of a file(s) ongoing upload operation.
DeleteFiles - To delete files.
CopyFiles - To copy files from one folder to another.
MoveFiles - To move files from one folder to another.
RenameFiles - To change files name.
GetFileShareURL - Returns a file share URL. Files protected by users group restrictions can this way be shared with anyone that does not belong to that group. The URL is linked to the user that invokes this function and will stop working if the user loses subsequent access to the related file.
Logout - Used to request user logout
| Function | Method | Response format(s) | |
|---|---|---|---|
CopyFiles |
POST | xml, json | |
Used to copy indexed documents from one folder to another. Request example: The message body must be a xml, UTF-8 encoded, document, containing the file(s) to copy identification (the fileURL item returned by the DBSearch and DBFolder methods), and the destination folder of the copy operation, organized as the next example xml file structure. Message body example, to copy two files in same request: <?xml version="1.0" encoding="UTF-8"?>
<dataset>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
<toFolder>C:\PDFs</toFolder>
</entry>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</dataset>
Possible response of above request example: <?xml version='1.0' encoding='UTF-8'?>
<response>
<entry>
<result>true</result>
<message>Operation succeeded</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
<newFileURL>/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/1956%20%2D%202.pdf</newFileURL>
</entry>
<entry>
<result>false</result>
<message>File not found</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</response>
A newFileURL item is returned for all the file copies that succeed, and reflect this new indexed file ID. Additional parameters: |
|||
| Parameter | Meaning | Notes | |
toFolder |
Optional, if same parameter specified by file, but required if xml body only specify the ID of the file to copy . Used to specify the destination folder of the copy operation. | ||
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
DBSearch |
GET | html, csv, rss, atom, xml, json | |
Used to execute a keywords search on all the PDFE database indexed metadata, or documents indexed text content. Equivalent to the GUI DBSearch scan mode. Request example: Response example: Similar to the DBFolder request result. Additional parameters: |
|||
| Parameter | Meaning | Notes | |
count |
Optional, default to 10. Used to specify the maximum number of documents metadata records to return. | ||
cs |
Optional, default to 0. Used to specify search operation case sensitivity. | Valid values: |
|
dir |
Optional, default to ASC. Used to specify the sort direction. | ASC - for ascending order DESC - for descending order. |
|
format |
Optional, default to "html". To specify the output format of the returned data. | Valid values are: html, csv, rss, atom, xml, json |
|
layout |
Optional, default to logged on user default layout. The layout numeric ID. Used to specify the layout to use while producing response. The layout specify what metadata fields are returned, and its data type. |
The available layout IDs can be obtained from the GetMetadataFieldsListInfo function returned data. | |
q |
Required. Parameter used to pass the search expression. | Must be utf-8 encoded. Support the boolean operators "and", "or" and "not". |
|
sort |
Optional, default to the filename field ID. The numeric ID of the metadata field to sort by. | The numeric metadata ID is a PDFE constant value that identify the PDFE indexed metadata fields. Can be obtained from the GetMetadataFieldsListInfo function returned data. | |
start |
Optional, default to 0. The first record index to return. | ||
stype |
Optional, default to 0. Used to pass the search type.. | Valid values: |
|
wo |
Optional, default to 0. Used to specify if search operation must use the option "Whole words only". | Valid values: |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
DeleteFiles |
POST | xml, json | |
Used to delete indexed files. Request example: The message body must be a xml, UTF-8 encoded, document, containing the file identification (the fileURL item returned by the DBSearch and DBFolder methods), organized as the next example xml file structure. Message body example, to delete two files in same request: <?xml version="1.0" encoding="UTF-8"?>
<dataset>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
</entry>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</dataset>
Possible response of above request example: <?xml version='1.0' encoding='UTF-8'?>
<response>
<entry>
<result>true</result>
<message>Operation succeeded</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
</entry>
<entry>
<result>false</result>
<message>File in use</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</response>
Additional parameters: |
|||
| Parameter | Meaning | Notes | |
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
GetFileShareURL |
GET | xml, json, html | |
Returns a file share URL. Files protected by users group restrictions can this way be shared with anyone that does not belong to that group. The URL is linked to the user that invokes this function and will stop working if the user loses subsequent access to the related file. Request example: Response example: <?xml version='1.0' encoding='UTF-8'?> <response> <result>true</result> <message></message> <ShareFileURL>http://localhost/pdfews/getfile/%BE%C7%A1%89%90%8D/016.pdf?sid=68FFB0233EFE2C1A47C89C1610422188F5F08A4206A0ABD17A212BA8B19A83</ShareFileURL> </response>Additional parameters: |
|||
| Parameter | Meaning | Notes | |
src |
Required. Used to pass the file ID to get the URL from. | This file ID correspond to the value of the fileURL variable, returned by the DBSearch and DBFolder functions. | |
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
GetMetadataFieldsListInfo |
GET | xml, json | |
Use this function to request the logged on user grid layouts list he as access to. This lists are the equivalent to the GUI grid layouts, and its information is used by many of the other api functions, to instruct server on what grid layout context execute the request. Request example: Response example: <?xml version='1.0' encoding='UTF-8'?> The above example result show two list, the generic PDFE Standard, and one Custom defined. The <default> item is used to indicate the ID of the list that's set as the default (the list selected in the Users and Permissions, available fields option, of the Group the logged on user is member of). This is the list that will be used by functions that require the layout parameter, needed to specify function execution context, if this parameter is not explicitly specified. Additional parameters: |
|||
| Parameter | Meaning | Notes | |
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
GetThumbnail |
GET | The image file format produced by the thumbnail generator. Image/png if Shell thumbnail handler used. | |
Used to request the thumbnail image of a document. Request example: |
|||
| Parameter | Meaning | Notes | |
src |
Required. Used to pass the file ID to get the thumbnail from. | This file ID correspond to the value of the fileURL variable, returned by the DBSearch and DBFolder functions. | |
cache |
Optional, default to 1. Instruct the web server if the requested image should be cached, in the configured cache folder, in order to be reused in further requests. The not cache option is normally useful when requesting enlarged versions of the thumbnail | Valid values: 0 - Doesn't cache image. 1 - Cache it. |
|
size |
Optional, default to small. If the thumbnail generator is set up to the Shell thumbnail handler option, this parameter is used to specify what the image size, of the two possibilities available, is being requested. | Valid values: small - To request the small resolution image. big - To request the big resolution image. |
|
c1,c2,c3,... |
Optional. Used when thumbnail generator is set up to External. It is used to pass custom command line parameters to the external application. More information can be found in the Additional options, thumbnails section. | ||
| Function | Method | Response format(s) | |
|---|---|---|---|
IsLoginNeeded |
GET | xml, json | |
Used to enquire web server if user must log on before perform any other database query operation. Log on is not required if there are no created users, or guest account is enabled (which makes an unlogged user a guest). This function returns also the ServerLoginChallenge value, needed for the Login function. Request example: Response example: <?xml version='1.0' encoding='UTF-8'?> <response> <result>true</result> <message></message> <ServerLoginChallenge>Additional parameters: |
|||
| Parameter | Meaning | Notes | |
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
Login |
POST | xml, json | |
Function used to log on a username/password pair identified user to the web interface. Request example: Username and password variables are passed in the POST method payload, using the standard name-value pairs and application/x-www-form-urlencoded mime type. The password value to pass must be the 32-digit hexadecimal number of the md5 hash of the concatenation of the server login challenge value with the plain text password value. This server login challenge value, only valid for 5 minutes after obtained, is sent with the IsLoginNeeded function query response. In pseudocode: The serverLoginChallenge value must be also included in the post message body. Here is one example of what must be sent: username=RTT&password=e8c42a296ddf1e9a536c2bc99cc0c5c4 The response will be a standard simple query response, result and message values, with an additional sessionID value if successful login. This sessionID is also sent as an http cookie in this response http header. If client doesn't support the http cookies mechanism, this sessionID value must be included, as an additional url "session" named parameter, in all subsequent queries, in order to properly link the user to his server active session. Response example: <?xml version='1.0' encoding='UTF-8'?>
<response>
<result>true</result>
<message>Welcome RTT</message>
<sessionID>{9740DF92-B2EE-4D94-A53C-7F59A8DC6C69}</sessionID>
Additional parameters: |
|||
| Parameter | Meaning | Notes | |
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
MoveFiles |
POST | xml, json | |
Used to move indexed files from one folder to another. Request example: The message body must be a xml, UTF-8 encoded, document, containing the file(s) to move identification (the fileURL item returned by the DBSearch and DBFolder methods), and the destination folder of the move operation, organized as the next example xml file structure. Message body example, to move two files in same request: <?xml version="1.0" encoding="UTF-8"?>
<dataset>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
<toFolder>C:\PDFs</toFolder>
</entry>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</dataset>
Possible response of above request example: <?xml version='1.0' encoding='UTF-8'?>
<response>
<entry>
<result>true</result>
<message>Operation succeeded</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
<newFileURL>/pdfews/getfile/%BE%C7%A1%AD%B9%BB%8E/1956%20%2D%202.pdf</newFileURL>
</entry>
<entry>
<result>false</result>
<message>The file exists</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</response>
A newFileURL item is returned for all the file moves that succeed, and reflect this new indexed file ID. Additional parameters: |
|||
| Parameter | Meaning | Notes | |
toFolder |
Optional, if same parameter specified by file, but required if xml body only specify the ID of the file to move . Used to specify the destination folder of the move operation. | ||
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
RenameFiles |
POST | xml, json | |
Used to give a new file name to indexed files. Request example: The message body must be a xml, UTF-8 encoded, document, containing the file identification (the fileURL item returned by the DBSearch and DBFolder methods), and the new file name, organized as the next example xml file structure. Message body example, to rename two files in same request: <?xml version="1.0" encoding="UTF-8"?>
<dataset>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
<newFilename>test.pdf</newFilename>
</entry>
<entry>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
<newFilename>newname.pdf</newFilename>
</entry>
</dataset>
Possible response of above request example: <?xml version='1.0' encoding='UTF-8'?>
<response>
<entry>
<result>true</result>
<message>Operation succeeded</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
<newFileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/test.pdf</newFileURL>
</entry>
<entry>
<result>false</result>
<message>File in use</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</response>
A newFileURL item is returned for all the file renames that succeed, and reflect the renamed new indexed file ID. Additional parameters: |
|||
| Parameter | Meaning | Notes | |
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
SetMetadata |
POST | xml, json | |
Used to edit indexed documents metadata. Multiple files can be edited with same request. Request example: The message body must be a xml, UTF-8 encoded, document, containing the file identification (the fileURL item returned by the DBSearch and DBFolder methods), and the metadata fields that effectively change, organized as the next example xml file structure. Message body example, to set two files metadata in same request: <?xml version="1.0" encoding="UTF-8"?>
<dataset>
<entry>
<Title>Document1 Title</Title>
<Keywords>Key1, key2</Keywords>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
</entry>
<entry>
<Title>Document2 Title</Title>
<Author>RTT</Author>
<Keywords>Key1, key2</Keywords>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</dataset>
Possible response of above request example: <?xml version='1.0' encoding='UTF-8'?>
<response>
<entry>
<result>true</result>
<message>Updated successfully</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%202.pdf</fileURL>
</entry>
<entry>
<result>false</result>
<message>File in use</message>
<fileURL>/pdfews/getfile/%BE%C7%A1%89%90%8D/1956%20%2D%203.pdf</fileURL>
</entry>
</response>
Additional parameters: |
|||
| Parameter | Meaning | Notes | |
layout |
Required. To specify the metadata fields layout context to use when setting the document(s) metadata. | This value is the ID item of the layout being used, returned in the GetMetadataFieldsListInfo response. |
|
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json |
|
| Function | Method | Response format(s) | |
|---|---|---|---|
Upload |
POST | xml, json, html | |
Used to upload files to a PDF Explorer indexed, and upload enabled, directory. This upload function accept any file type, but only PDF Explorer supported file types will be indexed. Multiple files can be upload in the same request. Request example: HTTP Post message body rules: Response example, for two file uploads in same request: <?xml version='1.0' encoding='UTF-8'?>
<response>
<item>
<result>true</result>
<message>Upload successfully</message>
<uploadID>a34ht12</uploadID>
</item>
<item>
<result>false</result>
<message>Unable to overwrite local file</message>
<uploadID>tbf4345</uploadID>
</item>
</response>
Additional parameters: |
|||
| Parameter | Meaning | Notes | |
folder |
Required, if i parameter not used instead. To pass file upload destination folder. | ||
i |
Required, if folder parameter not used instead. Parameter used as folder ID. It's a web interface specific implementation value and must be obtained from the GetDatabaseTree function returned data. | Can be replaced by the folder parameter, but it's much more web server friendly. | |
o_r |
Optional, default to 1. Used to specify the file replace method, for when a file with same name already exists in the target folder. | Valid values: 0 - to replace local file. 1 - to backup rename local file. |
|
format |
Optional, default to "xml". To specify the output format of the returned data. | Valid values are: xml, json, html |
|